读书笔记《Spring Microservices in Action》
2.1 The architect’s story: designing the microservice architecture
An architect’s role on a software project is to provide a working model of the problem that needs to be solved. The job of the architect is to provide the scaffolding against which developers will build their code so that all the pieces of the application fit together. When building a microservices architecture, a project’s architect focuses on three key tasks:
1 Decomposing the business problem
2 Establishing service granularity
3 Defining the service interfaces
~这就是微服务架构师的工作,好像也不是很复杂。
2.1.1 Decomposing the business problem
Breaking apart a business domain is an art form rather than a black-and-white science. Use the following guidelines for identifying and decomposing a business problem into microservice candidates:
1 Describe the business problem, and listen to the nouns you’re using to describe the problem. Using the same nouns over and over in describing the problem is usually an indication of a core business domain and an opportunity for a microservice.Examples of target nouns for the EagleEye domain from chapter 1 might look something like contracts, licenses, and assets.
2 Pay attention to the verbs. Verbs highlight actions and often represent the natural
contours of a problem domain. If you find yourself saying “transaction X needs to get data from thing A and thing B,” that usually indicates that multiple services are at play. If you apply to EagleEye the approach of watching for verbs,you might look for statements such as, “When Mike from desktop services is setting up a new PC, he looks up the number of licenses available for software X and, if licenses are available, installs the software. He then updates the number of licenses used in his tracking spreadsheet.” The key verbs here are looks and updates.
3 Look for data cohesion. As you break apart your business problem into discrete pieces, look for pieces of data that are highly related to one another. If suddenly, during the course of your conversation, you’re reading or updating data that’s radically different from what you’ve been discussing so far, you potentially have another service candidate. Microservices should completely own their data.
~如何分解问题域,其中的一些想法还有价值的,比如微服务完全拥有自己的数据等。
2.1.2 Establishing service granularity
When you’re building a microservice architecture, the question of granularity is important, but you can use the following concepts to determine the correct solution:
1 It’s better to start broad with your microservice and refactor to smaller services—It’s easy to go overboard when you begin your microservice journey and make everything a microservice. But decomposing the problem domain into small services often leads to premature complexity because microservices devolve into nothing more than fine-grained data services.
2 Focus first on how your services will interact with one another—This will help establish the coarse-grained interfaces of your problem domain. It’s easier to refactor from being too coarse-grained to being too fine-grained.
3 Service responsibilities will change over time as your understanding of the problem domain grows—Often, a microservice gains responsibilities as new application functionality is requested. What starts as a single microservice might grow into multiple services, with the original microservice acting as an orchestration layer for these new services and encapsulating their functionality from other parts of the application.
~系统一般的进化流程,首先所有的功能都在一个系统当中,随着系统功能的膨胀以及发布节奏的加快,单个系统上开发,测试,发布已经暴露出问题,这个时候,就可以将单个系统拆分两个或几个系统,每个系统都拥有自己的数据集。那么为什么要这样做呢?为什么不一开始就将系统规划为几个微服务呢,一是因为我们对系统的了解,也是逐步加深的;二是微服务管理也是有代价的,这样开发,测试的周期就会变长,另外运维,维护的成本也增加。
The smells of a bad microservice
Your microservices are heavily interdependent on one another—You find that the microservices in one part of the problem domain keep calling back and forth between each other to complete a single user request.
Your microservices become a collection of simple CRUD (Create, Replace, Update,Delete) services—Microservices are an expression of business logic and not an abstraction layer over your data sources. If your microservices do nothing but CRUD related logic, they’re probably too fine-grained.
~微服务的坏味道:一是微服务相互依赖,二是微服务成了一个增删减查的集合。
2.1.3 Talking to one another: service interfaces
In general, the following guidelines can be used for thinking about service interface design: 1 Embrace the REST philosophy—The REST approach to services is at heart the embracing of HTTP as the invocation protocol for the services and the use of standard HTTP verbs (GET, PUT, POST, and DELETE). Model your basic behaviors around these HTTP verbs.
2 Use URI’s to communicate intent—The URI you use as endpoints for the service should describe the different resources in your problem domain and provide a basic mechanism for relationships of resources within your problem domain.
3 Use JSON for your requests and responses—JavaScript Object Notation (in other words, JSON) is an extremely lightweight data-serialization protocol and is much easier to consume then XML. 4 Use HTTP status codes to communicate results—The HTTP protocol has a rich body of standard response codes to indicate the success or failure of a service. Learn these status codes and most importantly use them consistently across all your services.
~服务接口设计原则:REST,JSON,HTTP状态码。
2.2 When not to use microservices
Even with the lower cost of running these services in the cloud, the operational complexity of having to manage and monitor these servers can be tremendous.
If you’re building small, departmental-level applications or applications with a small user base, the complexity associated with building on a distributed model such as microservices might be more expense then it’s worth.
~一是说在云上运行微服务是低费用的,但是管理和监控这些服务的昂贵的,二是对于一些比较小的应用或者用户量小的应用应该杜绝使用微服务,这样做不值得。
3.3.2 Configuring the licensing service to use Spring Cloud Config
The bootstrap.yml file reads the application properties before any other configuration information used. In general, the bootstrap.yml file contains the application name for the service, the application profile, and the URI to connect to a Spring Cloud Config server. Any other configuration information that you want to keep local to the service (and not stored in Spring Cloud Config) can be set locally in the services in the application.yml file. Usually, the information you store in the application.yml file is configuration data that you might want to have available to a service even if the Spring Cloud Config service is unavailable. Both the bootstrap.yml and application.yml files are stored in a projects src/main/resources directory.
~微服务的两个配置文件bootstrap.yml, application.yml,并简要说明了这个配置文件的用途。
4.2.1 The architecture of service discovery
If, during the course of calling a service, the service call fails, the local service discovery cache is invalidated and the service discovery client will attempt to refresh its entries from the service discovery agent.
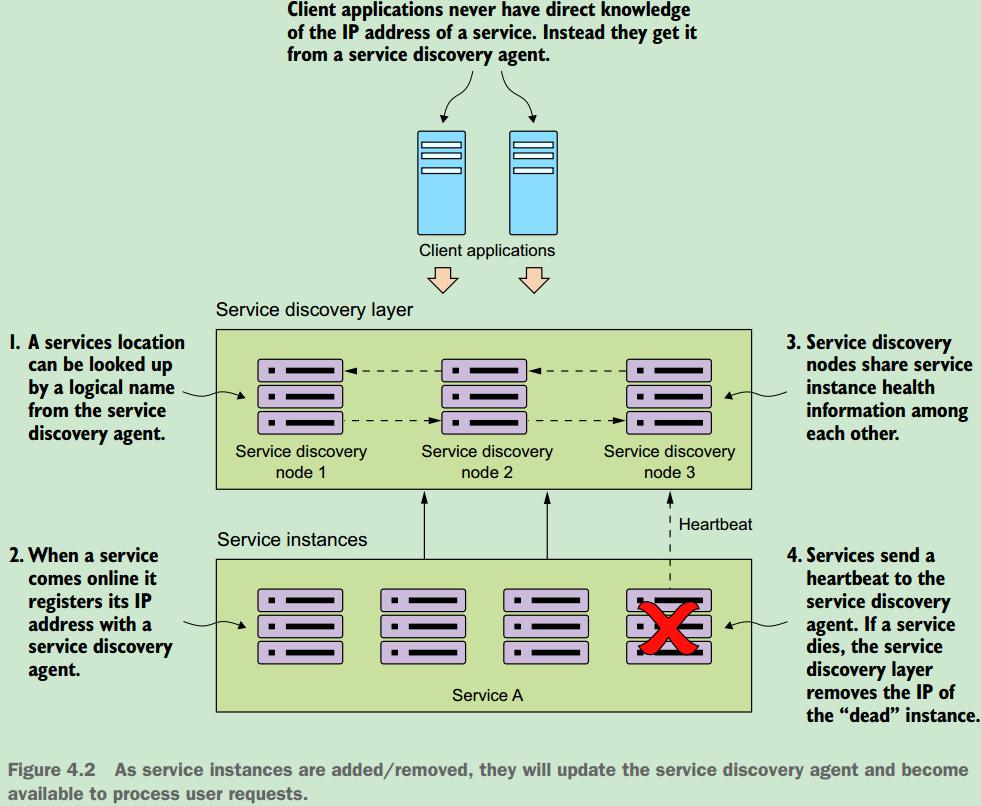
~当服务调用失败时,那么本地服务发现的缓存将全部失效,然后尝试着从服务发现层获取最新服务信息。
5.1 What are client-side resiliency patterns?
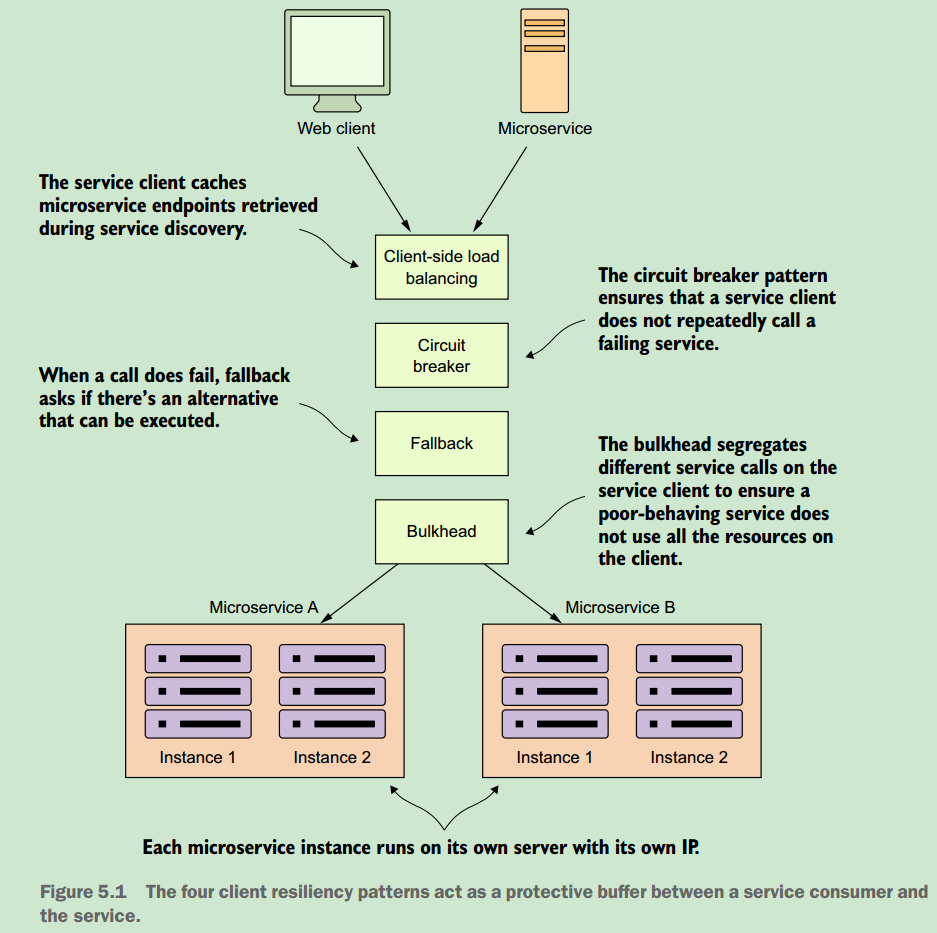
~四种客户端弹性模式:客户端负载均衡模式,熔断模式(也称为断路器模式),后备模式(也称为降级模式)。其中的舱壁模式,值得说说,利用该模式就不会让某一个性能有问题的外部服务调用消耗掉应用程序的所有资源,比如利用同一线程池的线程来处理所有的服务调用,那么某一服务运行缓慢时,将有可能消耗掉线程池中所有的线程,这将导致其他的服务调用失败。
5.7 Implementing the bulkhead pattern
@HystrixCommand(fallbackMethod = "buildFallbackLicenseList", threadPoolKey = "licenseByOrgThreadPool", threadPoolProperties = {@HystrixProperty(name = "coreSize",value="30"), @HystrixProperty(name="maxQueueSize", value="10")} ) public List<License> getLicensesByOrg(String organizationId){ return licenseRepository.findByOrganizationId(organizationId); }You can also set up a queue in front of the thread pool that will control how many requests will be allowed to back up when the threads in the thread pool are busy. This queue size is set by the maxQueueSize attribute. Once the number of requests exceeds the queue size, any additional requests to the thread pool will fail until there is room in the queue.
Note two things about the maxQueueSize attribute. First, if you set the value to -1,a Java SynchronousQueue will be used to hold all incoming requests. A synchronous queue will essentially enforce that you can never have more requests in process then the number of threads available in the thread pool. Setting the maxQueueSize to a value greater than one will cause Hystrix to use a Java LinkedBlockingQueue. The use of a LinkedBlockingQueue allows the developer to queue up requests even if all threads are busy processing requests.
The second thing to note is that the maxQueueSize attribute can only be set when the thread pool is first initialized (for example, at startup of the application). Hystrix does allow you to dynamically change the size of the queue by using the queueSizeRejectionThreshold attribute, but this attribute can only be set when the maxQueueSize attribute is a value greater than 0.
What’s the proper sizing for a custom thread pool? Netflix recommends the following formula: (requests per second at peak when the service is healthy * 99th percentile latency in seconds) + small amount of extra threads for overhead
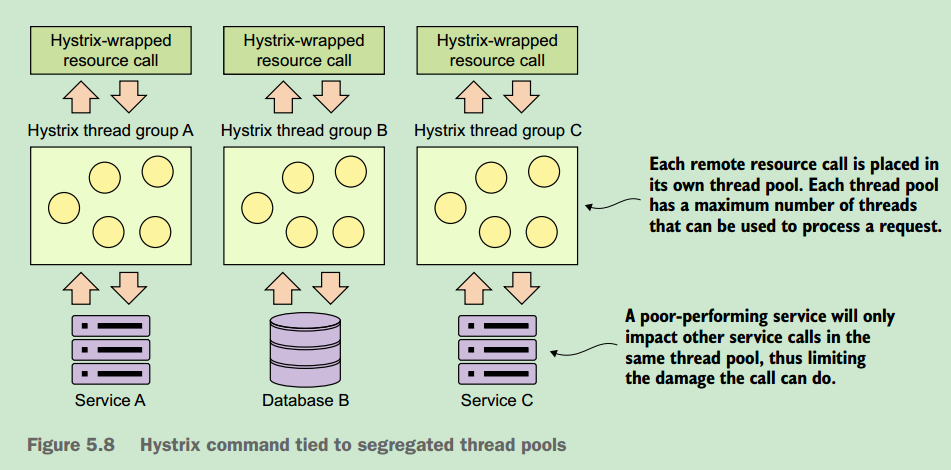
~舱壁模式的实现,其实就是创建多个线程池,让一个线程池只处理一个或几个服务的调用,这样就防止了某个服务出现性能问题甚至拓机时,也不会影响整个应用的其他服务调用,这样就只会影响使用同一线程池调用的服务,而不会影响整个应用程序。
~其中关于线程池数量的设置,这提供了一个方向,在Java并发编程实践那本书中,根据任务是计算密集型,还是IO密集型来设置线程数量,选择线程的数量。而这里是另外一种设置方法,则是根据服务的处理能力以及相应速度来设置,比如某服务高峰的请求数500,99%的任务的延迟小于或等于0.1秒,则线程池的数量可以设置为500*0.1,另外可以增加少量开销线程。
~99th percentile,第99百分位数,它使得至少有p%的数据项小于或等于这个值,且至少有(100-p)%的数据项大于或等于这个值。
5.8 Getting beyond the basics; fine-tuning Hystrix
When Hystrix has “tripped” the circuit breaker on a remote call, it will try to start a new window of activity. Every five seconds (this value is configurable), Hystrix will let a call through to the struggling service. If the call succeeds, Hystrix will reset the circuit breaker and start letting calls through again. If the call fails, Hystrix will keep the circuit breaker closed and try again in another five seconds.
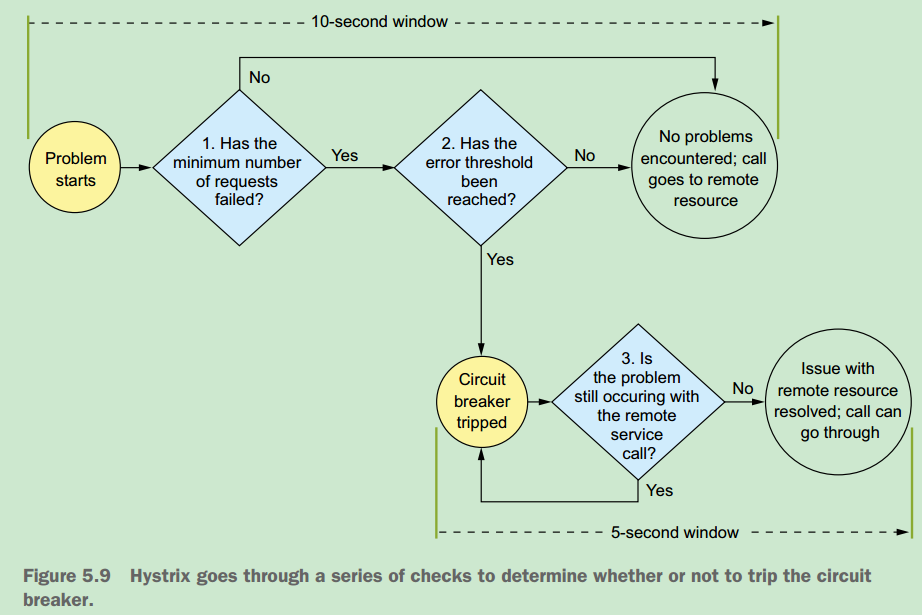
~触发熔断机制,有两个门槛,一是在检测窗口时间段内是否有一定数量请求处理失败,二是请求的失败率是否触及到阀值,如果达到这两个阀值,Hystrix将会触发熔断机制。当熔断触发后,Hystrix会持续检查服务是否已恢复,默认每五秒钟会将一个请求路由到目标服务,如果调用成功,则重置断路器,恢复对目标服务的访问,如果调用失败,则维持断路器关闭状态。
Listing 5.7 Configuring the behavior of a circuit breaker
@HystrixCommand( fallbackMethod = "buildFallbackLicenseList", threadPoolKey = "licenseByOrgThreadPool", threadPoolProperties ={ @HystrixProperty(name = "coreSize",value="30"), @HystrixProperty(name="maxQueueSize",value="10"), }, commandPoolProperties ={ @HystrixProperty( name="circuitBreaker.requestVolumeThreshold", value="10"), @HystrixProperty( name="circuitBreaker.errorThresholdPercentage", value="75"), @HystrixProperty( name="circuitBreaker.sleepWindowInMilliseconds", value="7000"), @HystrixProperty( name="metrics.rollingStats.timeInMilliseconds", value="15000"), @HystrixProperty( name="metrics.rollingStats.numBuckets", value="5")} ) public List<License> getLicensesByOrg(String organizationId){ logger.debug("getLicensesByOrg Correlation id: {}", UserContextHolder.getContext().getCorrelationId()); randomlyRunLong(); return licenseRepository.findByOrganizationId(organizationId); }The first property, circuitBreaker.requestVolumeTheshold, controls the amount of consecutive calls that must occur within a 10-second window before Hystrix will consider tripping the circuit breaker for the call. The second property, circuitBreaker.errorThresholdPercentage, is the percentage of calls that must fail(due to timeouts, an exception being thrown, or a HTTP 500 being returned) after thecircuitBreaker.requestVolumeThreshold value has been passed before the circuit breaker it tripped. The last property in the previous code example, circuitBreaker.sleepWindowInMilliseconds, is the amount of time Hystrix will sleep once the circuit breaker is tripped before Hystrix will allow another call through to see if the service is healthy again.
The last two Hystrix properties (metrics.rollingStats.timeInMilliseconds and metrics.rollingStats.numBuckets) are named a bit differently than the previous properties, but they still control the behavior of the circuit breaker. The first property, metrics.rollingStats.timeInMilliseconds, is used to control the size of the window that will be used by Hystrix to monitor for problems with a service call. The default value for this is 10,000 milliseconds (that is, 10 seconds).
The second property, metrics.rollingStats.numBuckets, controls the number of times statistics are collected in the window you’ve defined. Hystrix collects metrics in buckets during this window and checks the stats in those buckets to determine if the remote resource call is failing. The number of buckets defined must evenly divide into the overall number of milliseconds set for rollingStatus.inMilliseconds stats. For example, in your custom settings in the previous listing, Hystrix will use a 15-second window and collect statistics data into five buckets of three seconds in length.
~ circuitBreaker.requestVolumeThreshold,最小请求数,比如10秒须有10请求数,如果没有达到所设定的值,将不会触发熔断机制。
~ circuitBreaker.errorThresholdPercentage,调用目标服务的失败率,比如70%,也就是说目标服务的访问失败率超过70%,将有可能触发熔断机制,是否触发熔断机制,还要看是否达到了最小请求数。
~ circuitBreaker.sleepWindowInMilliseconds,休眠窗口的毫秒数,也就是说当熔断机制触发后,Hystrix将会休眠多少毫秒才会让请求通过去调用目标服务,用于检测目标服务是否已恢复。
~ metrics.rollingStats.timeInMilliseconds,用于度量的时间窗口毫秒数,默认为10秒,也就说10秒内最小请求数,目标服务的调用失败率达到设定的阀值,将会触发熔断机制。
~ metrics.rollingStats.numBuckets,收集统计数据的桶数,比如时间窗口设置为10秒,此参数设置为5个,则表示10秒内所有的目标服务的请求的统计数据将会均匀存放在5个桶中,平均每个桶存放2秒的统计数据。
5.8.1 Hystrix configuration revisited
The key thing to remember as you look at configuring your Hystrix environment is that you have three levels of configuration with Hystrix:
1 Default for the entire application
2 Default for the class
3 Thread-pool level defined within the class
~ 这个比较好理解,spring的配置项的优先级也是如此,首先是整个应用的配置项,而后类的上配置信息,最后也是最高优先级的类中的线程池级别的配置项。
5.9 Thread context and Hystrix
When an @HystrixCommand is executed, it can be run with two different isolation strategies: THREAD and SEMAPHORE. By default, Hystrix runs with a THREAD isolation.Each Hystrix command used to protect a call runs in an isolated thread pool that doesn’t share its context with the parent thread making the call. This means Hystrix can interrupt the execution of a thread under its control without worrying about interrupting any other activity associated with the parent thread doing the original invocation.
With SEMAPHORE-based isolation, Hystrix manages the distributed call protected by the @HystrixCommand annotation without starting a new thread and will interrupt the parent thread if the call times out. In a synchronous container server environment(Tomcat), interrupting the parent thread will cause an exception to be thrown that cannot be caught by the developer. This can lead to unexpected consequences for the developer writing the code because they can’t catch the thrown exception or do any resource cleanup or error handling.
To control the isolation setting for a command pool, you can set a commandProperties attribute on your @HystrixCommand annotation. For instance, if you wanted to set the isolation level on a Hystrix command to use a SEMAPHORE isolation,you’d use@HystrixCommand( commandProperties = { @HystrixProperty( name="execution.isolation.strategy", value="SEMAPHORE")})
~ @HystrixCommand有两种执行策略,分别为线程,信号量,不知道能不能翻译成信号量这个名词。线程执行策略容易理解,就是创建一个线程池,将服务的调用交给线程池中的线程去处理。而另外一种策略为信号量模式,就是由当前线程去执行,如果执行处理异常,且异常没有正确的捕获,那么将可能导致非预期的情况发生。
5.9.2 The HystrixConcurrencyStrategy in action?
Hystrix allows you to define a custom concurrency strategy that will wrap your Hystrix calls and allows you to inject any additional parent thread context into the threads managed by the Hystrix command. To implement a custom HystrixConcurrencyStrategy you need to carry out three actions:
1 Define your custom Hystrix Concurrency Strategy class
2 Define a Java Callable class to inject the UserContext into the Hystrix Command
3 Configure Spring Cloud to use your custom Hystrix Concurrency Strategy
~ 这个还得继续看看书中后续的内容才行。
~ 现在看,好像也比较容易理解,就是采用线程隔离模式执行策略时,如何将调用线程的上下文传递给线程池中的执行线程,让其线程能够利用调用线程的上下文做一些事情。
6.3 Configuring routes in Zuul
Zuul has several mechanisms to do this, including
1.Automated mapping of routes via service discovery
2.Manual mapping of routes using service discovery
3.Manual mapping of routes using static URLs
~ 是不是应该把实现细节也记录在这里呢?
If you want to see the routes being managed by the Zuul server, you can access the routes via the /routes endpoint on the Zuul server. This will return a listing of all the mappings on your service. Figure 6.4 shows the output from hitting http://localhost:5555/routes.
~查询路由信息
6.4 The real power of Zuul: filters?
Figure 6.11 The pre-, route, and post filters form a pipeline in which a client request flows through. As a request comes into Zuul, these filters can manipulate the incoming request.
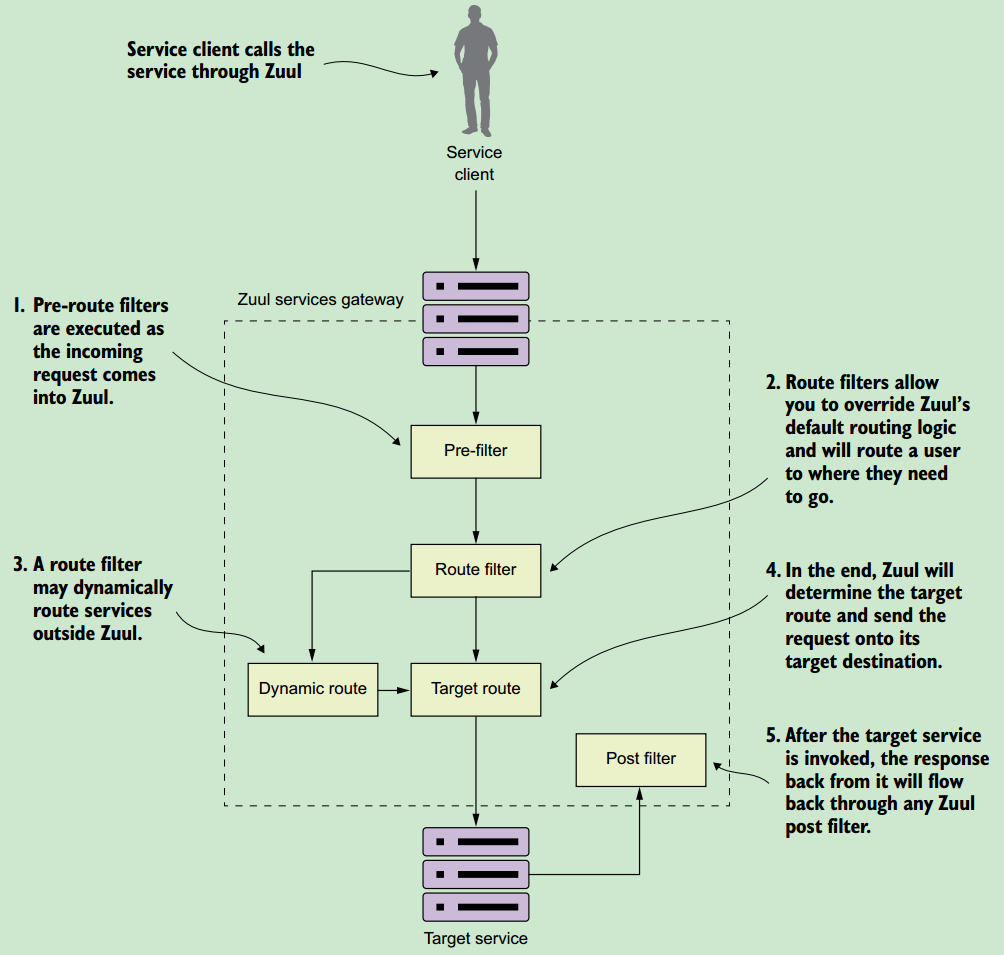
~ Zuul的过滤器,有前置过滤器,路由过滤器,后置过滤器,前置过滤器可以检查进入的请求,路由过滤器可以动态改变路由规则,将请求转发到其他服务,后置过滤器则对服务的响应进行处理。
8.2.1 The Spring Cloud Stream architecture
SOURCE
When a service gets ready to publish a message, it will publish the message using a source. A source is a Spring annotated interface that takes a Plain Old Java Object(POJO) that represents the message to be published. A source takes the message, serializes it (the default serialization is JSON), and publishes the message to a channel.
CHANNEL
A channel is an abstraction over the queue that’s going to hold the message after it has been published by the message producer or consumed by a message consumer. A channel name is always associated with a target queue name. However, that queue name is never directly exposed to the code. Instead the channel name is used in the code, which means that you can switch the queues the channel reads or writes from by changing the application’s configuration, not the application’s code.
BINDER
The binder is part of the Spring Cloud Stream framework. It’s the Spring code that talks to a specific message platform. The binder part of the Spring Cloud Stream framework allows you to work with messages without having to be exposed to platform specific libraries and APIs for publishing and consuming messages.
SINK
In Spring Cloud Stream, when a service receives a message from a queue, it does it through a sink. A sink listens to a channel for incoming messages and deserializes the message back into a plain old Java object. From there, the message can be processed by the business logic of the Spring service.
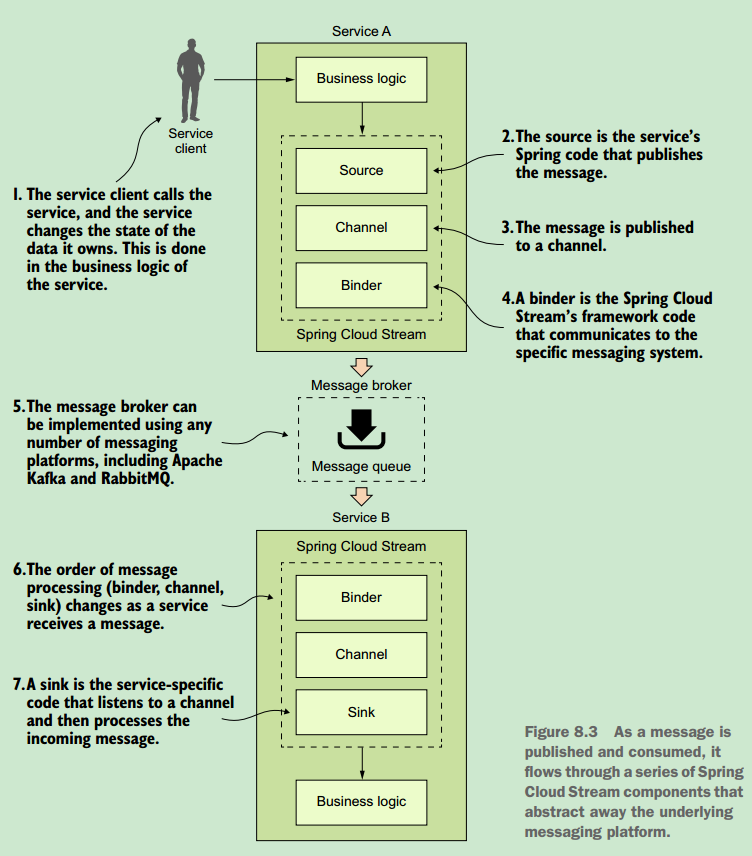
~ 其中的Source对象是讲pojo对象序列为json串,然后将消息发布到channel(通道),而Sink则是监听Channel,获取消息并反序列化为pojo对象,然后交由业务逻辑代码处理。
8.3.2 Writing the message consumer in the licensing service
you see the introduction of a new property called spring.cloud.stream.bindings.input.group. The group property defines the name of the consumer group that will be consuming the message.
The concept of a consumer group is this: You might have multiple services with each service having multiple instances listening to the same message queue. You want each unique service to process a copy of a message, but you only want one service instance within a group of service instances to consume and process a message. The group property identifies the consumer group that the service belongs to. As long as all the service instances have the same group name, Spring Cloud Stream and the underlying message broker will guarantee that only one copy of the message will be consumed by a service instance belonging to that group. In the case of your licensing service, the group property value will be called licensingGroup.
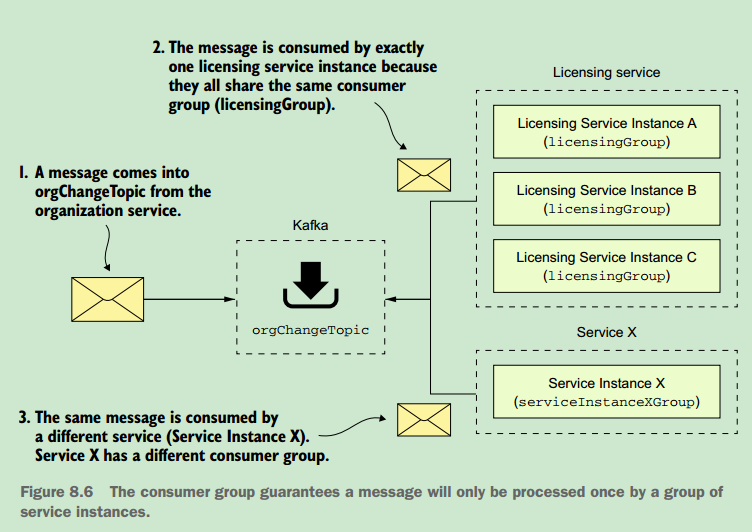
~ 消费者群组,主要是为了防止同一个服务的多个实例消费同一个消息多次,有了服务群组的概念,那么就能够限制同一个群主中的多个服务实例只能消费队列中的任何消息一次。
~ 当群组中某个消费退出(不论故障还是主动退出)或有新的消费者加入群组时,都将会触发群组负责的分区的再均衡。
8.4.2 Defining custom channels
However, if you want to define more than one channel for your application or you want to customize the names of your channels, you can define your own interface and expose as many input and output channels as your application needs.
The key takeaway from listing 8.12 is that for each custom input channel you want to expose, you mark a method that returns a SubscribableChannel class with the @Input annotation. If you want to define output channels for publishing messages,you’d use the @OutputChannel above the method that will be called. In the case of an output channel, the defined method will return a MessageChannel class instead of the SubscribableChannel class used with the input channel:@OutputChannel(“outboundOrg”) MessageChannel outboundOrg();

~ 如何客户化通道,其实就是创建新的通道。